DataForge
How Eric saved DataForge £40k/year in cloud infrastructure
DataForge’s AWS bill was growing 15% quarter-over-quarter, but their traffic was flat. Something was very wrong with their infrastructure spend.
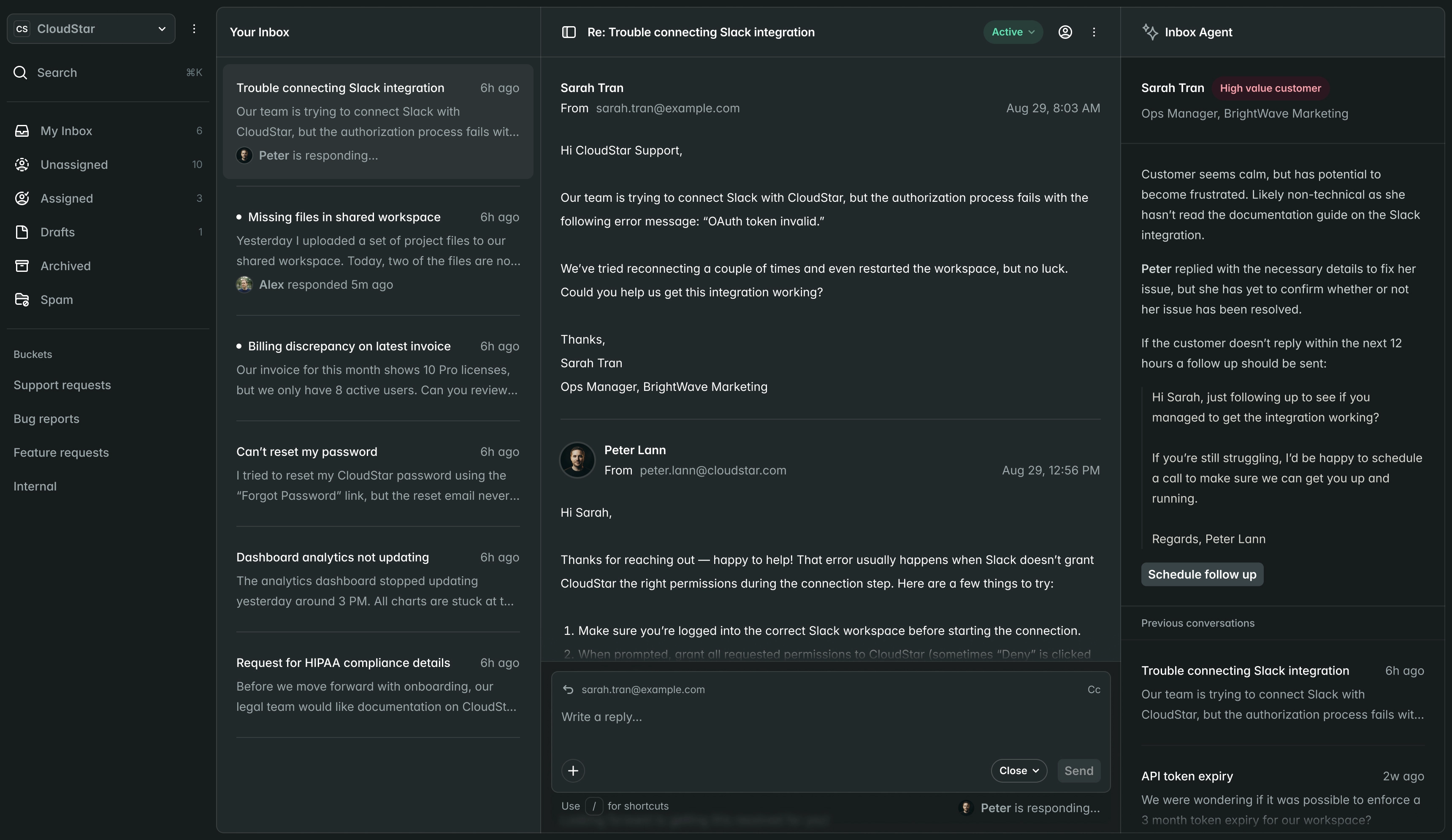
- £40k
- Annual savings
- 35%
- Compute cost reduction
- 0
- Performance impact
The challenge
DataForge had scaled their infrastructure aggressively during a traffic spike six months prior — and never scaled back down. They were running oversized EC2 instances, had orphaned EBS volumes accumulating storage charges, and their auto-scaling groups were configured with minimum counts that no longer matched actual traffic patterns.
The team knew they were overspending but were afraid to touch the infrastructure. The last time someone "optimised" their setup, it caused an outage. They needed someone who could right-size without breaking anything.
The approach
Eric conducted a comprehensive infrastructure audit over two weeks. He analysed 90 days of CloudWatch metrics, cross-referencing actual utilisation against provisioned capacity for every service in their stack.
The findings were clear: multiple instances were running below 10% CPU utilisation, over 200GB of orphaned EBS volumes were racking up charges, and auto-scaling thresholds were set based on a traffic pattern that no longer existed.
Rather than making sweeping changes, Eric implemented each optimisation incrementally — right-sizing one service at a time, monitoring for regressions, and only proceeding when stability was confirmed.
The results
Annual infrastructure spend was reduced by £40,000. Compute costs dropped 35%. Zero impact on performance or reliability — the system was simply right-sized to match actual demand.
Eric also set up automated cost monitoring alerts so the team would catch any future drift before it became a problem. DataForge now reviews their infrastructure spend quarterly using the dashboards he built.
Ready to see similar results?
Book a free 20-minute call to discuss your performance challenges. No obligation.